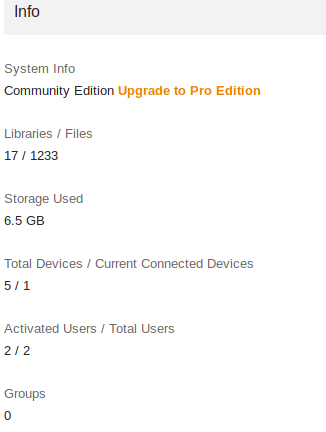
Thanks now it’s clear, I wrote a reply below before I read the whole thing and understood.
I’m not worried about few files missing as long as they will get updated on the next rsync, and after many of those at the end if last few files are missing that is OK, but I kind of thought rsync doesn’t see the files underneath the seafile-blocks but it does, I just rsync-ed my data and started an upload, and then did rysnc again and the ISO file was added, and then again more of it was sent, so it does see the files inside blocks because it clearly said the name of the file I was uploading, will post at the end. Makes me feel good.
-
And that’s why there is seaf-fsck script which check data latests hash compared with hash in database - and file contents but this is for long conversation.
I don’t mind long conversations hah. So let’s say I ran it like this for years and then do seaf-fsck, would it miss only the latest missing files or would something get corrupted every day, if it’s daily.
I did run fsck yesterday to test it out.
-
When you use --repair flag on seaf-fsck, then seafile with restore library history to hash saved in database. That’s why seafile manual saying “Backup database first”.
well maybe I need a bit more reading to do :), but that’s the path I’m taking database first then data because I don’t want to be rebuilding anything in the database anytime soon.
-
Conclusion: When you restore all backups and run seaf-fsck, modified file(while running backup) will be lost - but will be backedup on next backup period.
Oh ok well, I was reading and reaplying along and I just saw this line, so I should be good, at least 99.2% , thank you much appreciated.
-
Also thanks for letting me know how you do backups, this helps a lot. I also don’t want to do downtime for other people so I will do live rsyncs with database first
-
And thanks for letting me know that seafile stop and start script needs checking up on, since this is going to be a cronjob I will not be there to check if it’s up or down, so better not stop it like you said, what if it doesn’t start 
So here it is. What I did was rsync, then started uploading ISO and rsync twice, and then stop upload and rsync and then it gets deleted, nice.
I guess you don’t need to see this, but I will leave it here for someone else to see, in case they need to know.
me@seafile:~$ sudo rsync -avzHP --delete /opt/seafile-data backup.backup:/home/me
sending incremental file list
sent 154,902 bytes received 1,673 bytes 104,383.33 bytes/sec
total size is 2,950,509,888 speedup is 18,844.07
me@seafile:~$ sudo rsync -avzHP --delete /opt/seafile-data backup.backup:/home/me
sending incremental file list
seafile-data/logs/var-log/nginx/access.log.1
90,741 100% 10.73MB/s 0:00:00 (xfr#1, ir-chk=1042/1071)
seafile-data/logs/var-log/nginx/seahub.access.log.1
330,587 100% 26.27MB/s 0:00:00 (xfr#2, ir-chk=1019/1071)
seafile-data/seafile/seafile-data/httptemp/
seafile-data/seafile/seafile-data/httptemp/debian-8.11.1-amd64-DVD-1.isoJRLTG1
506,534 100% 11.23MB/s 0:00:00 (xfr#3, ir-chk=1004/1090)
sent 662,252 bytes received 5,341 bytes 445,062.00 bytes/sec
total size is 2,951,017,436 speedup is 4,420.38
me@seafile:~$ sudo rsync -avzHP --delete /opt/seafile-data backup.backup:/home/me
sending incremental file list
seafile-data/seafile/seafile-data/httptemp/debian-8.11.1-amd64-DVD-1.isoJRLTG1
3,029,670 100% 15.28MB/s 0:00:00 (xfr#1, ir-chk=1004/1090)
sent 1,287,218 bytes received 6,004 bytes 862,148.00 bytes/sec
total size is 2,953,540,572 speedup is 2,283.86
me@seafile:~$ sudo rsync -avzHP --delete /opt/seafile-data backup.backup:/home/me
sending incremental file list
deleting seafile-data/seafile/seafile-data/httptemp/debian-8.11.1-amd64-DVD-1.isoJRLTG1
seafile-data/logs/var-log/nginx/error.log.1
80,320 100% 75.93MB/s 0:00:00 (xfr#1, ir-chk=1035/1070)
seafile-data/logs/var-log/nginx/seafhttp.access.log.1
696,883 100% 221.53MB/s 0:00:00 (xfr#2, ir-chk=1027/1070)
seafile-data/seafile/seafile-data/httptemp/
sent 155,543 bytes received 7,506 bytes 108,699.33 bytes/sec
total size is 2,950,511,390 speedup is 18,095.86
me@seafile:~$ sudo rsync -avzHP --delete /opt/seafile-data backup.backup:/home/me
sending incremental file list
sent 154,903 bytes received 1,677 bytes 313,160.00 bytes/sec
total size is 2,950,511,390 speedup is 18,843.48